

The Blog
- Third Party Maintenance
- IT Network Maintenance
- Server Maintenance
- IT Storage Maintenance
- Network Monitoring Software
- Network Discovery Software
- Network Mapping Software
- Network Flow Analysis
- Network Bandwidth Analyzer
- Network Path Monitoring
- IT Infrastructure Managed Services
- Hardware Monitoring
- IT Asset Disposition
- Data Center Relocation Services
- Data Center Remote Hands
- IT Deployment Services
- Move Add Change Managed Service
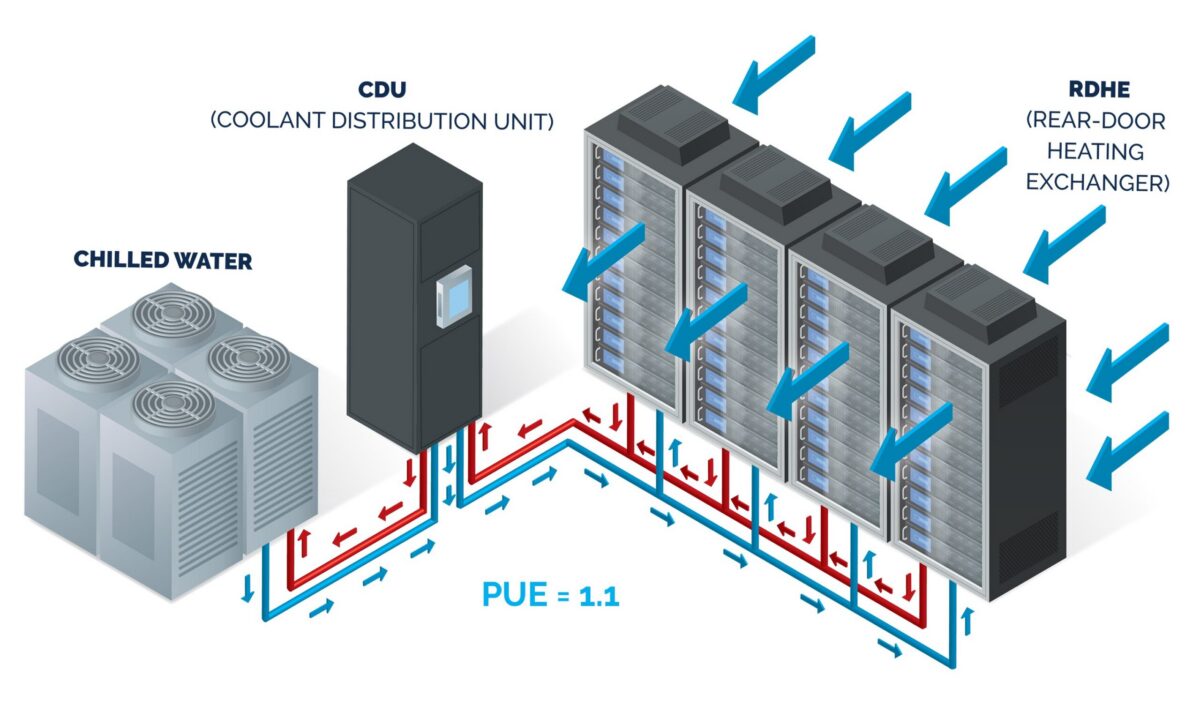
- Data Center Liquid Cooling
-

Software-Defined Data Center (SDDC) – Components and Benefits
The enterprise IT sector is experiencing an era of change with the use of the software-defined data center (SDDC). Physical infrastructure was once the domain of “wires and pliers” technicians; with SDDC, if you want to deploy data center assets, it is seemingly as easy…
-

Hybrid Cloud Best Practices – Manage your Environment with Ease
A hybrid cloud environment, which spans private cloud instances and public cloud platforms, offers distinct advantages over an exclusively private or public cloud architecture. However, hybrid clouds can be challenging to set up and manage. Issues include complexity, visibility, performance, security, and cost. This article…
-

AI’s Infrastructure Problem Isn’t Just GPUs — It’s Memory and Storage
AI investment is accelerating at a pace most infrastructure roadmaps were never built to support. While headlines tend to focus on GPU shortages, a more persistent and less visible challenge is emerging behind the scenes: a tightening global supply of core memory and storage components….
-

Data Center Consolidation Strategy: Creating an Effective Project Plan
What do you see and hear when you look at racks of servers in a data center? You hear a lot of humming and see rows of blinking lights, and probably imagine that these machines are all hard at work. You’d be mistaken. Historically, enterprise…
-

Server Performance Optimization – Tips & Identifying Common Issues
We’ve all been frustrated by websites and apps that lag or take a while to load. What’s extra frustrating is that it can be difficult to tell what exactly is causing the slowdown. It could be a network problem, a sluggish database, or a server…
-

How to Make Data Centers More Sustainable – Tips and Best Practices
Data centers consume significant amounts of electrical power. Their outsized carbon footprints make it challenging for a data center to be sustainable, in terms of the environment and resource consumption. They also use a great deal of water. Data center equipment typically turns into e-waste,…
-

Data Center Migration Challenges and Relocation Risks: How to Overcome Them
If you manage a data center, you often deal with situations that might seem difficult to overcome. Such frustrations often arise during data center migrations and relocations. There are many things to get right, but also so many things that can go wrong. We’ll look…
-

Data Center Migration Best Practices – Ensuring a Smooth Relocation
A data center migration involves moving IT assets from one data center environment to another. In some cases, this means physically relocating hardware, although the process could also be a migration from on-premises hosting to the cloud or simply moving a virtual machine (VM) from…